
Connecting street-levelperception with aerial views forSpatial Intelligence
Incoming Tenure-track Assistant Professor (Starting August 2026)
at Southern University of Science and Technology (SUSTech)
I am actively recruiting motivated PhD and MSc students, as well as research assistants, to work on spatial intelligence, computer vision, and robotics. If this aligns with your interests, feel free to email me at zimin.xia@epfl.ch.
I am Zimin Xia, a postdoctoral researcher with the Visual Intelligence for Transportation Lab at EPFL, advised by Prof. Alexandre Alahi. My research lies at the intersection of computer vision and mobile robotics, with a focus on ground-to-aerial cross-view localization, mapping, and representation learning for autonomous systems. More broadly, I am interested in methods that remain reliable beyond tightly curated benchmarks.
Before joining EPFL, I earned my PhD with the Intelligent Vehicles Group at TU Delft under the supervision of Prof. Julian F. P. Kooij and Prof. Dariu M. Gavrila, while collaborating with the Autonomous Driving Department at TomTom in Amsterdam. Earlier, I studied Geomatics Engineering at the University of Stuttgart and Wuhan University and also spent time at Carl Zeiss.
Research interests
Vision Read more Hide
Spatial intelligence, originally conceived as a human cognitive ability, refers to the capacity to perceive the visual world accurately, to perform transformations upon one's perceptions, and to re-create aspects of one's visual experience even in the absence of relevant physical stimuli (Gardner, 2011).
Extending beyond human cognition, this capability now underpins the development of Embodied AI: physical systems that integrate artificial intelligence to perceive and interact with the physical world.
By instilling this distinctly human faculty of spatial intelligence into machines, we are reshaping how societies move, sense, and connect across altitudes. In ground-level transportation, spatial intelligence empowers autonomous vehicles to perceive complex urban environments, localize themselves amid dynamic traffic, and make real-time decisions that enhance safety and efficiency on our roads. Within the rapidly expanding low-altitude economy, autonomous drones rely on spatial intelligence to navigate dense environments, inspect and maintain critical infrastructure, deliver goods, and support disaster response.
Together, these advances mark a paradigm shift toward embodied AI agents that extend human perception and action across all layers of the physical world.
Selected publication
Jean Piaget, the Swiss psychologist who pioneered the study of children's cognitive development, observed that a key aspect of emerging spatial intelligence is the ability to coordinate spatial relationships and find one's way between different locales (Piaget, 1957).
Hence, self-localization, the task of identifying one's ego-location within an external reference frame, constitutes a fundamental problem in the development of spatial intelligence.
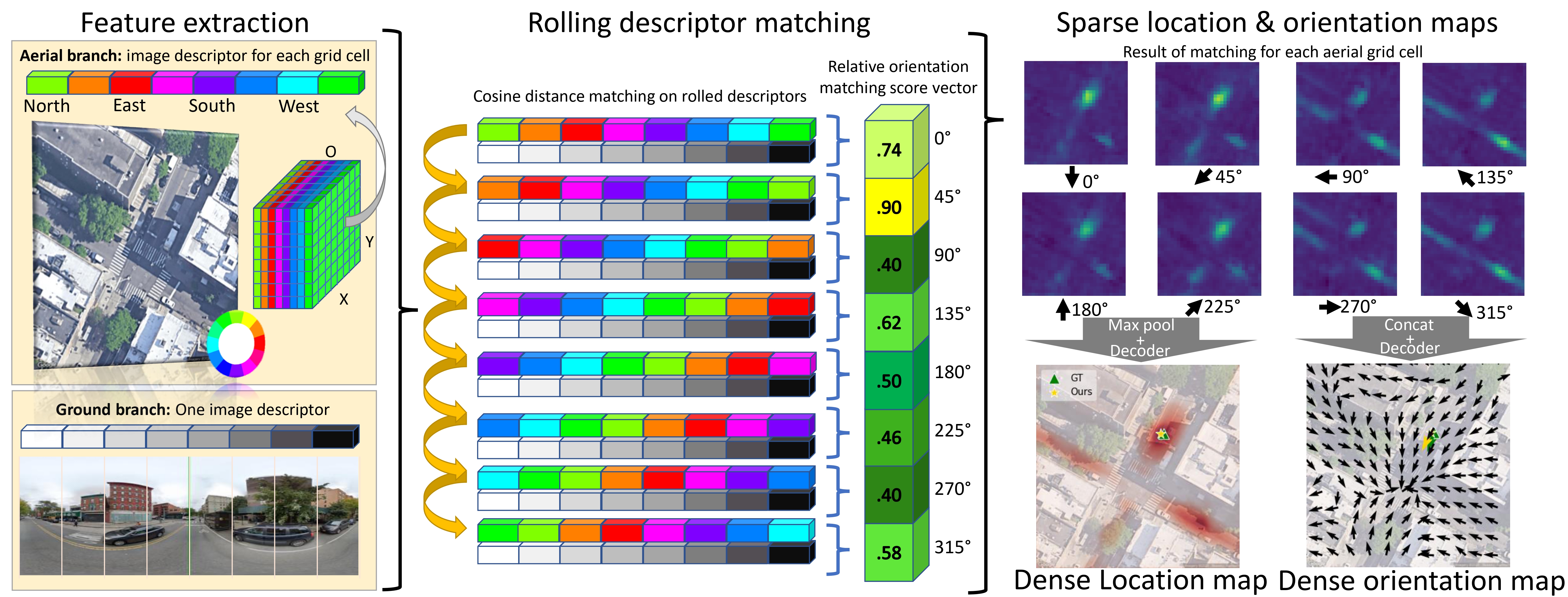
Loc2: Interpretable Cross-View Localization via Depth-Lifted Local Feature Matching
Learns interpretable ground-to-aerial correspondences, lifts them with monocular depth, and estimates pose through scale-aware alignment.

FG2: Fine-Grained Cross-View Localization by Fine-Grained Feature Matching
Pushes cross-view localization toward fine-grained pixel correspondences between ground-level perception and aerial imagery.
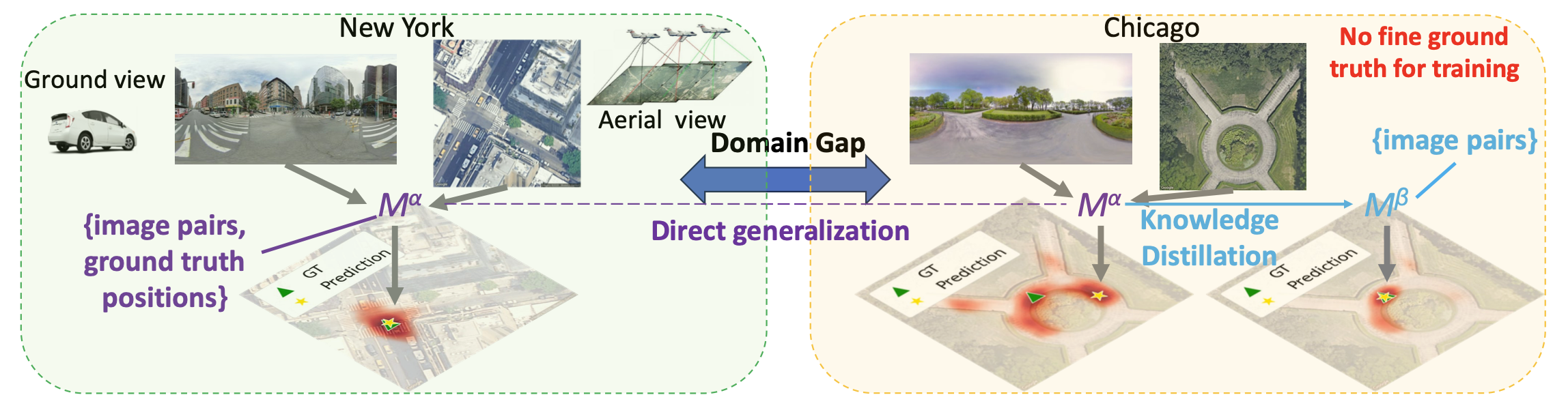
Adapting Fine-Grained Cross-View Localization to Areas without Fine Ground Truth
Adapts fine-grained cross-view localization to regions where accurate localization labels are unavailable.
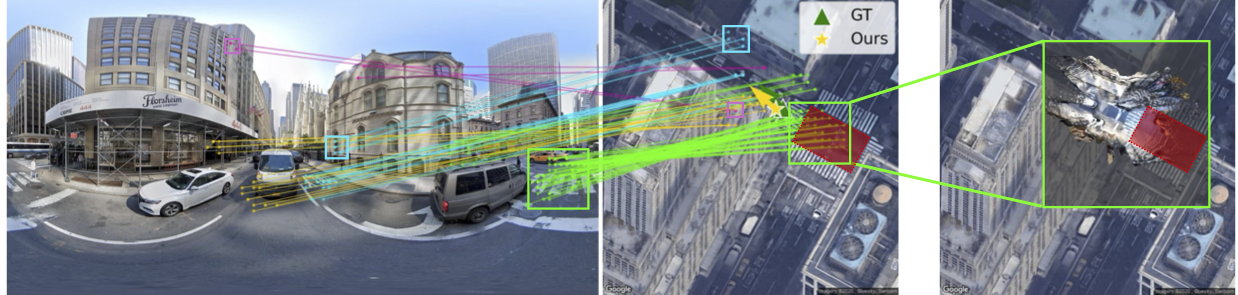
Convolutional Cross-View Pose Estimation
Formulates cross-view pose estimation with convolutional feature matching and spatial reasoning, turning dense ground-to-aerial evidence into a structured estimate of camera pose.
SliceMatch: Geometry-guided Aggregation for Cross-View Pose Estimation
Introduces geometry-guided aggregation to better align ground and aerial evidence for pose estimation.
Slice-specific cross-view attention and precomputed aerial slice masks allow the model to build pose-dependent descriptors efficiently, improving localization accuracy while keeping inference efficient.

Visual Cross-View Metric Localization with Dense Uncertainty Estimates
Models dense uncertainty to improve metric localization when cross-view evidence is ambiguous or noisy.
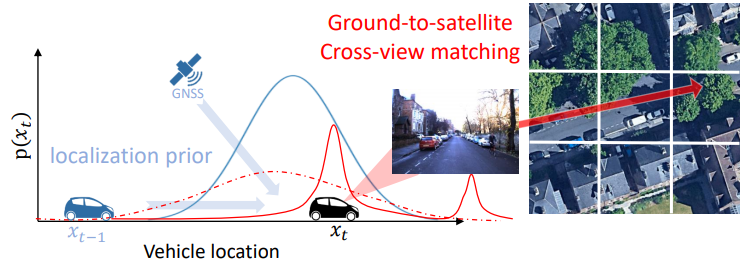
Cross-View Matching for Vehicle Localization by Learning Geographically Local Representations
Learns geographically local features to improve localization by embedding a spatial prior into the representation.

Geographically Local Representation Learning with a Spatial Prior for Visual Localization
An early step toward learning location-aware representations that remain grounded in geographic structure.
Invited talk
From Retrieval to Precision: Fine-Grained Cross-View Geo-Localization
Invited speaker for the tutorial Beyond Vision: Multimodal Perspectives for Cross-View Geo-Localization at WACV 2026.
References
- Howard Gardner. Frames of Mind: The Theory of Multiple Intelligences. Basic Books, 2011.
- Jean Piaget, Baerbel Inhelder, F. J. Langdon, and J. L. Lunzer. "The Child's Conception of Space." British Journal of Educational Studies 5.2 (1957), pp. 187-189. DOI: 10.2307/3118882.